在日常的开发中,android 的消息机制作为系统运行的根本机制之一,显得十分的重要。
从 handler 发送消息开始
查看源码,handler的post、send方法最终都会走到
public final boolean sendmessagedelayed(message msg, long delaymillis) {
if (delaymillis < 0) {
delaymillis = 0;
}
return sendmessageattime(msg, systemclock.uptimemillis() delaymillis);
}
sendmessagedelayed 会走到
private boolean enqueuemessage(messagequeue queue, message msg, long uptimemillis) {
msg.target = this;
if (masynchronous) {
msg.setasynchronous(true);
}
return queue.enqueuemessage(msg, uptimemillis);
}
这里可以设置 message 为异步消息
查看 queue 的 enqueuemessage 方法, 我们剥离出核心代码:
if (p == null || when == 0 || when < p.when) {
// new head, wake up the event queue if blocked.
msg.next = p;
mmessages = msg;
needwake = mblocked;
}
如果是新的队列头,直接插入队列
如果队列里面已经有消息了,执行如下逻辑
needwake = mblocked && p.target == null && msg.isasynchronous();
message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needwake && p.isasynchronous()) {
needwake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
插入消息的时候,一般不会唤醒消息队列。如果消息是异步的,并且队列头不是一个异步消息的时候,会唤醒消息队列
if (needwake) {
nativewake(mptr);
}
消息队列的具体唤醒过程我们暂时不细看。把关注点移到 looper 上。looper在执行的时候具体执行了什么逻辑呢?查看 looper.java 的 looper() 方法
looper 方法中有一个死循环, 在死循环中,会获取下一个 message
for (;;) {
message msg = queue.next(); // might block
}
if (msg != null && msg.target == null) {
// stalled by a barrier. find the next asynchronous message in the queue.
do {
prevmsg = msg;
msg = msg.next;
} while (msg != null && !msg.isasynchronous());
当存在一个 barrier 消息的时候,会寻找队列中下一个异步任务。而不是按照顺序。 例如3个消息,1,2,3, 2 是异步消息。如果不存在barrier的时候,next的顺序就是 1,2,3 但是如果存在barrier的时候,则是 2,1,3
if (msg != null) {
if (now < msg.when) {
// next message is not ready. set a timeout to wake up when it is ready.
nextpolltimeoutmillis = (int) math.min(msg.when - now, integer.max_value);
} else {
// got a message.
mblocked = false;
if (prevmsg != null) {
prevmsg.next = msg.next;
} else {
mmessages = msg.next;
}
msg.next = null;
if (debug) log.v(tag, "returning message: " msg);
msg.markinuse();
return msg;
}
} else {
// no more messages.
nextpolltimeoutmillis = -1;
}
这里如果 next 的 message 不为空,就返回,并且将它移出队列 在 messagequeue 为空的时候,会顺便去处理一下 add 过的 idlehandler, 处理一些不重要的消息
for (int i = 0; i < pendingidlehandlercount; i ) {
final idlehandler idler = mpendingidlehandlers[i];
mpendingidlehandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueidle();
} catch (throwable t) {
log.wtf(tag, "idlehandler threw exception", t);
}
if (!keep) {
synchronized (this) {
midlehandlers.remove(idler);
}
}
查看 idlehandler 的源码。
* callback interface for discovering when a thread is going to block
* waiting for more messages.
*/
public static interface idlehandler {
/**
* called when the message queue has run out of messages and will now
* wait for more. return true to keep your idle handler active, false
* to have it removed. this may be called if there are still messages
* pending in the queue, but they are all scheduled to be dispatched
* after the current time.
*/
boolean queueidle();
}
当 queueidle() 为 false 的时候,会将它从 midlehandlers 中 remove,仔细思考下,我们其实可以利用idlehandler实现不少功能, 例如
looper.myqueue().addidlehandler(new messagequeue.idlehandler() {
@override
public boolean queueidle() {
return false
}
});
我们可以在 queueidle 中,趁着没有消息要处理,统计一下页面的渲染时间(消息发送完了说明ui已经渲染完了),或者算一下屏幕是否长时间没操作等等。
拿到 message 对象后,会将 message 分发到对应的 target 去
msg.target.dispatchmessage(msg);
查看源码
public void dispatchmessage(message msg) {
if (msg.callback != null) {
handlecallback(msg);
} else {
if (mcallback != null) {
if (mcallback.handlemessage(msg)) {
return;
}
}
handlemessage(msg);
}
}
当 msg 的 callback 不为 null 的时候,即通过 post(runnable) 发送信息的会执行 handlercallback(msg) 方法。如果 mcallback 不为 null并且 handlemessage 的结果为 false,则执行 handlemessage 方法。否则会停止分发。
private static void handlecallback(message message) {
message.callback.run();
}
查看 handlercallback 方法源码, callback 会得到执行。到这里基本的android消息机制就分析完了,简而言之就是,handler 不断的将message发送到一 根据时间进行排序的优先队列里面,而线程中的 looper 则不停的从mq里面取出消息,分发到相应的目标handler执行。
为什么主线程不卡?
分析完基本的消息机制,既然 looper 的 looper 方法是一个for(;;;)循环,那么新的问题提出来了。为什么android会在主线程使用死循环?执行死循环的时候为什么主线程的阻塞没有导致cpu占用的暴增?�
继续分析在源码中我们没有分析的部分:
- 消息队列构造的时候是否调用了jni部分
- nativewake、nativepollonce这些方法的作用是什么
先查看mq的构造方法:
messagequeue(boolean quitallowed) {
mquitallowed = quitallowed;
mptr = nativeinit();
}
会发现消息队列还是和native层有关系,继续查看android/platform/frameworks/base/core/jni/android_os_messagequeue_nativeinit.cpp中nativeinit的实现:
static jlong android_os_messagequeue_nativeinit(jnienv* env, jclass clazz) {
nativemessagequeue* nativemessagequeue = new nativemessagequeue();
if (!nativemessagequeue) {
jnithrowruntimeexception(env, "unable to allocate native queue");
return 0;
}
nativemessagequeue->incstrong(env);
return reinterpret_cast(nativemessagequeue);
}
这里会发现我们初始化了一个 nativemessagequeue ,查看这个消息队列的构造函数
nativemessagequeue::nativemessagequeue() :
mpollenv(null), mpollobj(null), mexceptionobj(null) {
mlooper = looper::getforthread();
if (mlooper == null) {
mlooper = new looper(false);
looper::setforthread(mlooper);
}
}
这里会发现在mq中初始化了 native 的 looper 对象,查看android/platform/framework/native/libs/utils/looper.cpp中 looper 对象的构造函数
// 简化后的代码
looper::looper(bool allownoncallbacks) :
mallownoncallbacks(allownoncallbacks), msendingmessage(false),
mresponseindex(0), mnextmessageuptime(llong_max) {
int wakefds[2];
int result = pipe(wakefds);
mwakereadpipefd = wakefds[0];
mwakewritepipefd = wakefds[1];
result = fcntl(mwakereadpipefd, f_setfl, o_nonblock);
result = fcntl(mwakewritepipefd, f_setfl, o_nonblock);
mepollfd = epoll_create(epoll_size_hint);
struct epoll_event eventitem;
memset(& eventitem, 0, sizeof(epoll_event));
eventitem.events = epollin;
eventitem.data.fd = mwakereadpipefd;
result = epoll_ctl(mepollfd, epoll_ctl_add, mwakereadpipefd, & eventitem);
}
这里我们会发现,在 native 层创建了一个epoll,并且对 epoll 的 event 事件进行了监听。
什么是epoll
在继续分析源码之前,我们先分析一下,什么是epoll
epoll是linux中的一种io多路复用方式,也叫做event-driver-io。
linux的select 多路复用io通过一个select()调用来监视文件描述符的数组,然后轮询这个数组。如果有io事件,就进行处理。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。
epoll在select的基础上(实际是在poll的基础上)做了改进,epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可。
另一个本质的改进在于epoll采用基于事件的就绪通知方式(设置回调)。在select中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知
关于epoll和select,可以举一个例子来表达意思。select的情况和班长告诉全班同学交作业类似,会挨个去询问作业是否完成,如果没有完成,班长会继续询问。
而epoll的情况则是班长询问的时候只是统计了待交作业的人数,然后告诉同学作业完成的时候告诉把作业放在某处,然后喊一下他。然后班长每次都去这个地方收作业。
大致了解了epoll之后,我们继续查看nativepollonce方法,同理,会调用native looper的pollonce方法
while (mresponseindex < mresponses.size()) {
const response& response = mresponses.itemat(mresponseindex );
int ident = response.request.ident;
if (ident >= 0) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
if (outfd != null) *outfd = fd;
if (outevents != null) *outevents = events;
if (outdata != null) *outdata = data;
return ident;
}
}
在pollonce中,会先处理没有callback的response(alooper_poll_callback = -2),处理完后会执行pollinner方法
// 移除了部分细节处理和日志代码
// 添加了分析源码的日志
int looper::pollinner(int timeoutmillis) {
if (timeoutmillis != 0 && mnextmessageuptime != llong_max) {
nsecs_t now = systemtime(system_time_monotonic);
int messagetimeoutmillis = tomillisecondtimeoutdelay(now, mnextmessageuptime);
if (messagetimeoutmillis >= 0
&& (timeoutmillis < 0 || messagetimeoutmillis < timeoutmillis)) {
timeoutmillis = messagetimeoutmillis;
}
}
// poll.
int result = alooper_poll_wake;
mresponses.clear();
mresponseindex = 0;
struct epoll_event eventitems[epoll_max_events];
// 等待事件发生或者超时
int eventcount = epoll_wait(mepollfd, eventitems, epoll_max_events, timeoutmillis);
// acquire lock.
mlock.lock();
// check for poll error.
// epoll 事件小于0, 发生错误
if (eventcount < 0) {
if (errno == eintr) {
goto done;
}
result = alooper_poll_error;
goto done;
}
if (eventcount == 0) {
// epoll事件为0,超时,直接跳转到done
result = alooper_poll_timeout;
goto done;
}
//循环遍历,处理所有的事件
for (int i = 0; i < eventcount; i ) {
int fd = eventitems[i].data.fd;
uint32_t epollevents = eventitems[i].events;
if (fd == mwakereadpipefd) {
if (epollevents & epollin) {
awoken(); //唤醒,读取管道里面的事件
} else {
}
} else {
ssize_t requestindex = mrequests.indexofkey(fd);
if (requestindex >= 0) {
int events = 0;
// 处理request,生成response对象,push到相应的vector
pushresponse(events, mrequests.valueat(requestindex));
} else {
}
}
}
done: ;
// invoke pending message callbacks.
// 发生超时的逻辑处理
mnextmessageuptime = llong_max;
while (mmessageenvelopes.size() != 0) {
// 处理native端的message
nsecs_t now = systemtime(system_time_monotonic);
const messageenvelope& messageenvelope = mmessageenvelopes.itemat(0);
if (messageenvelope.uptime <= now) {
// remove the envelope from the list.
// we keep a strong reference to the handler until the call to handlemessage
// finishes. then we drop it so that the handler can be deleted *before*
// we reacquire our lock.
{ // obtain handler
sp handler = messageenvelope.handler;
message message = messageenvelope.message;
mmessageenvelopes.removeat(0);
msendingmessage = true;
mlock.unlock();
handler->handlemessage(message); // 处理消息事件
} // release handler
mlock.lock();
msendingmessage = false;
result = alooper_poll_callback; // 设置回调
} else {
// the last message left at the head of the queue determines the next wakeup time.
mnextmessageuptime = messageenvelope.uptime;
break;
}
}
// release lock.
mlock.unlock();
// invoke all response callbacks.
// 执行回调
for (size_t i = 0; i < mresponses.size(); i ) {
response& response = mresponses.edititemat(i);
if (response.request.ident == alooper_poll_callback) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
int callbackresult = response.request.callback->handleevent(fd, events, data);
if (callbackresult == 0) {
removefd(fd); //移除fd
}
// clear the callback reference in the response structure promptly because we
// will not clear the response vector itself until the next poll.
response.request.callback.clear(); // 清除reponse引用的回调方法
result = alooper_poll_callback; // 发生回调
}
}
return result;
}
看到这里,我们其实可以看出来整体消息模型由 native 和 java 2层组成,2层各自有自己的消息系统。 java层通过调用 pollonce 来达到调用底层epoll 让死循环进入阻塞休眠的状态,以避免浪费cpu, 所以这也解释了为什么android looper的死循环为什么不会让主线程cpu占用率飙升。
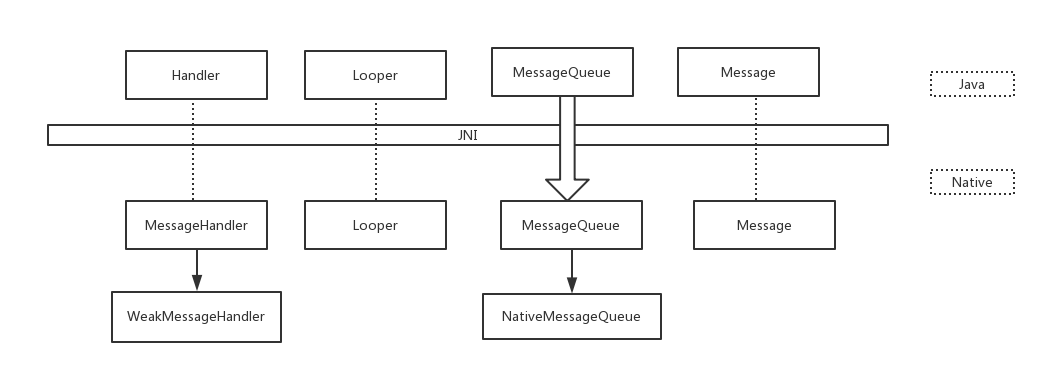
java层和native层的对应图如下:
备注
- java 层和 native 层通过 messagequeue 里面持有一个 native 的messagequeue 对象进行交互。weakmessagehandler 继承自messagehandler,nativemessagequeue 继承自 messagequeue
- java 层和 native 层实质是各自维护了一套相似的消息系统。c层发出的消息和java层发出的消息可以没有任何关系。所以 framework 层只是很巧的利用了底层 epoll 的机制达到阻塞的目的。
- 通过 pollonce 的分析,可以发现消息的处理其实是有顺序的,首先是处理native message,然后处理native request,最后才会执行java层,处理java层的message
可以在子线程中创建handler吗?为什么每个线程只会有一个looper?
在很多时候,我们可以遇到这2个问题。既然看了 handler 的源码,那么,我们就顺便分析一下这 2 个问题。
查看handler的构造方法,无参构造方法最后会调用
public handler(callback callback, boolean async) {
mlooper = looper.mylooper();
if (mlooper == null) {
throw new runtimeexception(
"can't create handler inside thread that has not called looper.prepare()");
}
mqueue = mlooper.mqueue;
mcallback = callback;
masynchronous = async;
}
可以看到,这里会直接获取looper
public static @nullable looper mylooper() {
return sthreadlocal.get();
}
这里会把每个 looper 存到相应的threadlocal对象中,如果子线程直接创建了handler,looper 就会是一个null,所以会直接跑出一个"can't create handler inside thread that has not called looper.prepare()"的runtimeexception
那么我们是何时把looper放入threadlocal对象的呢?可以在looper.prepare()中找到答案
private static void prepare(boolean quitallowed) {
if (sthreadlocal.get() != null) {
throw new runtimeexception("only one looper may be created per thread");
}
sthreadlocal.set(new looper(quitallowed));
}
这也解释了,在每个 thread 中,只会存在一个 looper 对象。如果我们想在子线程中正常创建 handler,就需要提前运行当前线程的 looper,调用
looper.prepare()
就不会抛出异常了。
总结
消息机制作为 android 的基础,还是非常有深入了解的必要。对于我们遇到handler发送消息的时候跑出的系统异常的排查也很有意义。
特别感谢
本次源码的阅读过程中,遇到了很多不了解的问题例如epoll,这里非常感谢io哥(查看io哥大佬)助和指导。让我在某些细节问题上暂时绕过和恍然大悟。