相关推荐
-
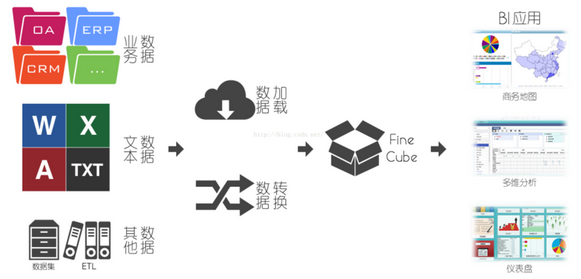
常用的几种大数据架构剖析 随着大数据技术的发展,数据挖掘、数据探索等专有名词曝光度越来越高,但是在类似于hadoop系列的大数据分析系统大行其道之前,数据分析工作已经经历了长足的发展,尤其是以bi系统为主的...
-
虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。 本文将介绍大数据系统一个最基本的组件:处理框架。处理...
-
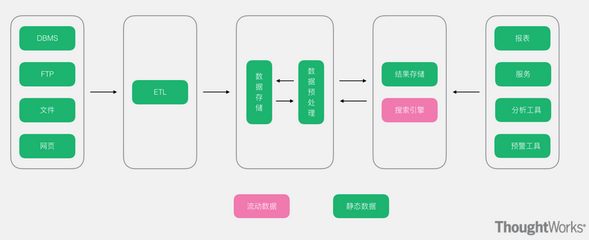
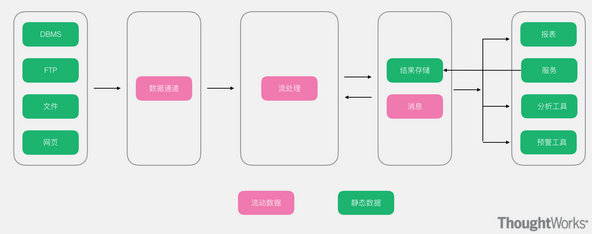
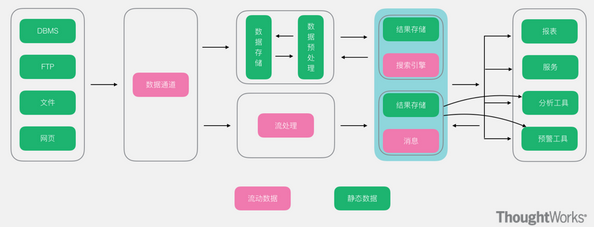
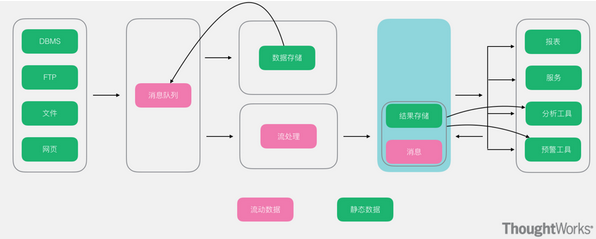
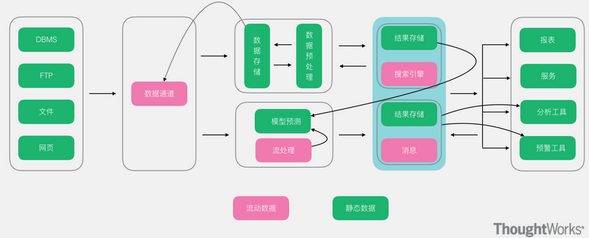
大数据常用的架构 随着多年的大数据的技术发展和积累,越来越多的人发现各个公司所使用的大数据技术大致可以分为两大类,分别是离线处理技术和实时处理技术,要么个别公司只有离线处理技术,要么个别公司只有实时...
-
解读主流大数据架构 前几天读到白发川的一篇文章《对比解读五种主流...参考:常用的几种大数据架构剖析 引用了作者文中的一些图片,凯发k8国际的版权归作者所有。 从互联网上下载引用的图片,也归原作者所有。 1. ...
-
通过合理设计和搭建大数据架构,可以提高数据处理的效率和质量,使得企业和组织能够更好地利用大数据来支持决策和创新。数据源可以是结构化数据,如关系数据库中的表格数据,也可以是非结构化数据,如日志文件、...
-
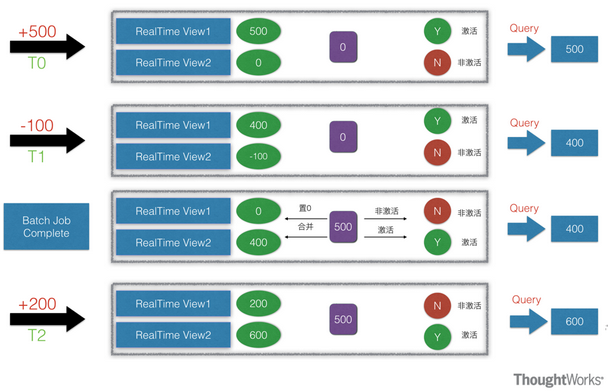
kappa 架构是由 linkedin 的前首席工程师杰伊·克雷普斯(jay kreps)提出的一种架构思想。克雷普斯是几个著名开源项目(包括 apache kafka 和 apache samza 这样的流处理系统)的作者之一。 kreps 提出了一个改进 ...
-
下图是阿里巴巴大数据系统架构图: 一、数据采集层 数据采集主要分成以下三块数据: 1,web 端日志 2,app 端日志 3,第三方数据(比如 mysql 增量数据同步) web 端和 app 端的日志数据都需要制定各个场景下的...
-
前几天读到白发川的一篇文章《对比解读五种主流大数据架构的数据分析能力》,文中详细总结了各类数据架构的应用以及原理。作为一名在数据仓库耕耘多年的技术人员,对于其中的一些技术细节还是破解兴趣的,所以随着...
-
管理系统是一种通过计算机技术实现的用于组织、监控和控制各种活动的软件系统。这些系统通常被设计用来提高效率、减少错误、加强安全性,同时提供数据和信息支持。以下是一些常见类型的管理系统: 学校管理系统: 用于学校或教育机构的学生信息、教职员工信息、课程管理、成绩记录、考勤管理等。学校管理系统帮助提高学校的组织效率和信息管理水平。 人力资源管理系统(hrm): 用于处理组织内的人事信息,包括员工招聘、培训记录、薪资管理、绩效评估等。hrm系统有助于企业更有效地管理人力资源,提高员工的工作效率和满意度。 库存管理系统: 用于追踪和管理商品或原材料的库存。这种系统可以帮助企业避免库存过剩或不足的问题,提高供应链的效率。 客户关系管理系统(crm): 用于管理与客户之间的关系,包括客户信息、沟通记录、销售机会跟踪等。crm系统有助于企业更好地理解客户需求,提高客户满意度和保留率。 医院管理系统: 用于管理医院或医疗机构的患者信息、医生排班、药品库存等。这种系统可以提高医疗服务的质量和效率。 财务管理系统: 用于记录和管理组织的财务信息,包括会计凭证、财务报表、预算管理等。财务管理系统
-
gb2312字符集 作用:国家简体中文字符集,兼容ascii。 位数:使用2个字节表示,能表示7445个符号,包括6763个汉字,几乎覆盖所有高频率汉字。 范围:高字节从a1到f7, 低字节从a1到fe。将高字节和低字节分别加上0xa0即可得到编码。 gbk字符集 作用:它是gb2312的扩展,加入对繁体字的支持,兼容gb2312。 位数:使用2个字节表示,可表示21886个字符。 范围:高字节从81到fe,低字节从40到fe。 gb18030字符集 作用:它解决了中文、日文、朝鲜语等的编码,兼容gbk。 位数:它采用变字节表示(1 ascii,2,4字节)。可表示27484个文字。 范围:1字节从00到7f; 2字节高字节从81到fe,低字节从40到7e和80到fe;4字节第一三字节从81到fe,第二四字节从30到39。
-
毕业设计,安卓app,基于java开发的学生成绩课件管理系统app,包括pc端和安卓anroid手机app,内含java完整源码 安卓andriod学生成绩课件管理系统 系统开发环境: windows myclipse(服务器端) eclipse(手机客户端) mysql数据库 服务器也可以用eclipse或者idea等工具,客户端也可以采用android studio工具! 系统客户端和服务器端架构技术: 界面层,业务逻辑层,数据层3层分离技术,mvc设计思想! 服务器和客户端数据通信格式:json格式,采用servlet方式 【服务器端采用ssh框架,请自己启动tomcat服务器,hibernate会自动生成数据库表的哈!】 hibernate生成数据库表后,只需要在admin管理员表中加个测试账号密码就可以登录后台了哈! 下面是数据库的字段说明: 班级: 班级编号,班级名称,开办日期,班主任 学生: 学号,登录密码,所在班级,姓名,性别,出生日期,学生照片,联系电话,家庭地址 老师: 教师编号,登录密码,姓名,性别,出生日期,联系电话,邮件,地址,
-
管理系统是一种通过计算机技术实现的用于组织、监控和控制各种活动的软件系统。这些系统通常被设计用来提高效率、减少错误、加强安全性,同时提供数据和信息支持。以下是一些常见类型的管理系统: 学校管理系统: 用于学校或教育机构的学生信息、教职员工信息、课程管理、成绩记录、考勤管理等。学校管理系统帮助提高学校的组织效率和信息管理水平。 人力资源管理系统(hrm): 用于处理组织内的人事信息,包括员工招聘、培训记录、薪资管理、绩效评估等。hrm系统有助于企业更有效地管理人力资源,提高员工的工作效率和满意度。 库存管理系统: 用于追踪和管理商品或原材料的库存。这种系统可以帮助企业避免库存过剩或不足的问题,提高供应链的效率。 客户关系管理系统(crm): 用于管理与客户之间的关系,包括客户信息、沟通记录、销售机会跟踪等。crm系统有助于企业更好地理解客户需求,提高客户满意度和保留率。 医院管理系统: 用于管理医院或医疗机构的患者信息、医生排班、药品库存等。这种系统可以提高医疗服务的质量和效率。 财务管理系统: 用于记录和管理组织的财务信息,包括会计凭证、财务报表、预算管理等。财务管理系统
-
软件开发设计:php、qt、应用软件开发、系统软件开发、移动应用开发、网站开发c 、java、python、web、c#等语言的项目开发与学习资料 硬件与设备:单片机、eda、proteus、rtos、包括计算机硬件、服务器、网络设备、存储设备、移动设备等 操作系统:linux、ios、树莓派、安卓开发、微机操作系统、网络操作系统、分布式操作系统等。此外,还有嵌入式操作系统、智能操作系统等。 网络与通信:数据传输、信号处理、网络协议、网络与通信硬件、网络安全网络与通信是一个非常广泛的领域,它涉及到计算机科学、电子工程、数学等多个学科的知识。 云计算与大数据:数据集、包括云计算平台、大数据分析、人工智能、机器学习等,云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。
-
企业定价策略分销策略与促销策略.docx
-
管理系统是一种通过计算机技术实现的用于组织、监控和控制各种活动的软件系统。这些系统通常被设计用来提高效率、减少错误、加强安全性,同时提供数据和信息支持。以下是一些常见类型的管理系统: 学校管理系统: 用于学校或教育机构的学生信息、教职员工信息、课程管理、成绩记录、考勤管理等。学校管理系统帮助提高学校的组织效率和信息管理水平。 人力资源管理系统(hrm): 用于处理组织内的人事信息,包括员工招聘、培训记录、薪资管理、绩效评估等。hrm系统有助于企业更有效地管理人力资源,提高员工的工作效率和满意度。 库存管理系统: 用于追踪和管理商品或原材料的库存。这种系统可以帮助企业避免库存过剩或不足的问题,提高供应链的效率。 客户关系管理系统(crm): 用于管理与客户之间的关系,包括客户信息、沟通记录、销售机会跟踪等。crm系统有助于企业更好地理解客户需求,提高客户满意度和保留率。 医院管理系统: 用于管理医院或医疗机构的患者信息、医生排班、药品库存等。这种系统可以提高医疗服务的质量和效率。 财务管理系统: 用于记录和管理组织的财务信息,包括会计凭证、财务报表、预算管理等。财务管理系统
-
安川 a1000 闭环矢量设定表
-
软件开发设计:php、qt、应用软件开发、系统软件开发、移动应用开发、网站开发c 、java、python、web、c#等语言的项目开发与学习资料 硬件与设备:单片机、eda、proteus、rtos、包括计算机硬件、服务器、网络设备、存储设备、移动设备等 操作系统:linux、ios、树莓派、安卓开发、微机操作系统、网络操作系统、分布式操作系统等。此外,还有嵌入式操作系统、智能操作系统等。 网络与通信:数据传输、信号处理、网络协议、网络与通信硬件、网络安全网络与通信是一个非常广泛的领域,它涉及到计算机科学、电子工程、数学等多个学科的知识。 云计算与大数据:数据集、包括云计算平台、大数据分析、人工智能、机器学习等,云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。
-
软件开发设计:php、qt、应用软件开发、系统软件开发、移动应用开发、网站开发c 、java、python、web、c#等语言的项目开发与学习资料 硬件与设备:单片机、eda、proteus、rtos、包括计算机硬件、服务器、网络设备、存储设备、移动设备等 操作系统:linux、ios、树莓派、安卓开发、微机操作系统、网络操作系统、分布式操作系统等。此外,还有嵌入式操作系统、智能操作系统等。 网络与通信:数据传输、信号处理、网络协议、网络与通信硬件、网络安全网络与通信是一个非常广泛的领域,它涉及到计算机科学、电子工程、数学等多个学科的知识。 云计算与大数据:数据集、包括云计算平台、大数据分析、人工智能、机器学习等,云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。
-
数据集介绍,下载本资源后,界面如下: 有两个文件夹一个是存放数据集的文件。 数据集介绍: 一共含有:130个类别,数据集图片数量超过:7700张,包含:'abigail_williams_(fate)', 'aegis_(persona)', 'aisaka_taiga', 'albedo', 'anastasia_(idolmaster)', 'aqua_(konosuba)', 'arcueid_brunestud', 'asia_argento', 'astolfo_(fate)', 'asuna_(sao)', 'atago_(azur_lane)', 'ayanami_rei', 'belfast_(azur_lane)', 'bremerton_(azur_lane)', 'c.c', 'chitanda_eru', 'chloe_von_einzbern', 'cleveland_(azur_lane)', 'd.va_(overwatch)', 'dido_(azur_lane)', 'emilia_rezero', 'enterprise_(azur_lane)',